- Download and prepare benchmark datasets for code readability evaluation
- Compare different LLM models (GPT-4, GPT-3.5, GPT-4 Turbo) for classification accuracy
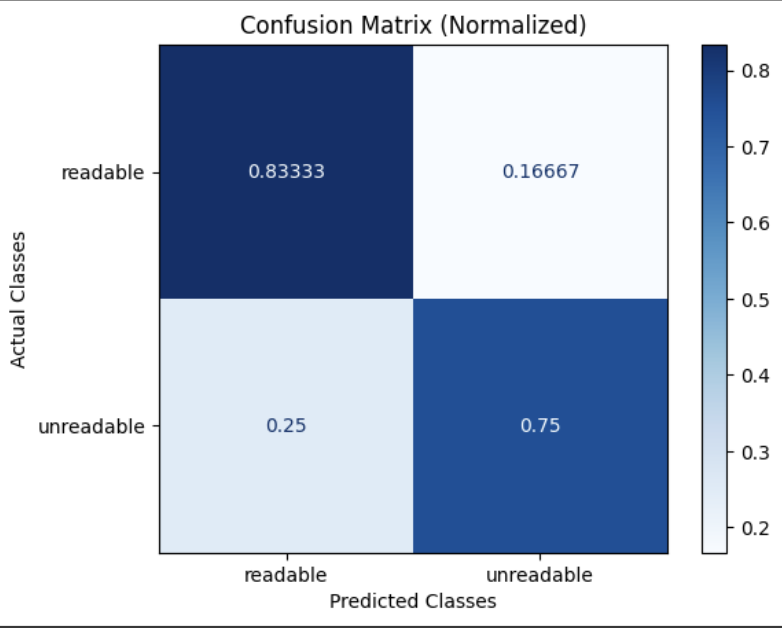
- Analyze results with confusion matrices and detailed reports
- Get explanations for LLM classifications to understand decision-making
Notebook Walkthrough
We will go through key code snippets on this page. To follow the full tutorial, check out the full notebook.
Google Colab
colab.research.google.com
Download Benchmark Dataset
Configure Evaluation
Run Code Readability Classification
Run readability classifications against a subset of the data.Evaluate Results and Plot Confusion Matrix
Evaluate the predictions against human-labeled ground-truth readability labels.